Una delle attività più complesse annesse alla definizione di progetto software è la stima dei tempi, e quindi dei costi.
Tale stima, sia che si gestisca il progetto secondo i dettami Agili che secondo i dettami del project management più tradizionale, basa molto della sua accuratezza sui dati statici, ovvero sulla conoscenza del contesto operativo, sul Team a cui verrà affidato il progetto, e altri fattori collegati.
Ora, concentrandosi sulle tecniche Agili e, tralasciando stime di costi che piacciono molto ai PM ma che si rilevano decisamente poco affidabili (una per tutte quella basata sul numero di linee di codice ipoteticamente necessarie, alias LOC), vediamo come effettuare una “stima intelligente”.
Prima di tutto è utile chiarire che non è sufficiente effettuare una sola stima, ma ne servono almeno due:
- - Release Estimation (long-medium time), che viene utilizzata per la stima dei tempi (costi) relativi all’intera release e porta con se la stima della Velocity, ovvero la capacità di sviluppo del Team;
- - Iteration Estimation (short time), che viene utilizzata per la stima dei tempi (e parzialmente dei costi) durante un’iterazione.
Quando si approccia un nuovo progetto è necessario avere una stima di massima del tempo (costi) necessario per il suo delivery: attenzione, non parliamo solo della scrittura del codice, ma dell’intero ciclo di sviluppo connesso ad un nuovo prodotto! Tale stima consente al management di valutare il rapporto costi/benefici e decidere se imbarcarsi concretamente nella realizzazione del nuovo sistema.
Questo è lo scopo della Release Estimation, che avviene “pesando” i Goal di progetto, tipicamente Epic e User Story, grazie agli Story Point. Lo scopo è quello di stimare la complessità delle User Story che, una volta sommate, daranno la stima complessiva del progetto. A questo punto, è necessario calcolare la Velocity, ovvero la capacità di sviluppo/realizzazione del Team per singola Iterazione. Questo esercizio può essere fatto almeno in tre modi diversi:
- - Per affinità di progetto, ovvero si calcola la Velocity considerando quella ottenuta per un progetto di complessità similare;
- - Per Team, ovvero si calcola in base alla Velocity tipica del Team;
- - Per stima empirica, utilizzata quando non si possono applicare le altre due tecniche e l’unica possibilità è quella di affidarsi alle competenze di chi effettua la prima valutazione.
Una volta calcolati gli Story Point totali e la Velocity, si possono calcolare il numero totale di iterazioni necessarie e da qui i tempi ed i costi relativi. Chiaramente la stima sarà rivista ad ogni iterazione per ridurre il cosiddetto “Cono di Incertezza”.
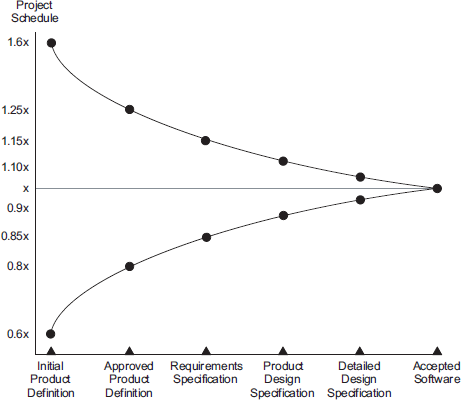
Cono di Incertezza
Sempre restando nel campo della Release Estimation, in alternativa agli Story Point è possibile effettuare la stima basandosi sugli Ideal Day, ovvero ipotizzando quanti “giorni ideali” (quindi pieni e senza distrazioni) sono necessari per completare il progetto. Sebbene questo approccio sembri più semplice è anche più rischioso: prima di tutto si ha la tendenza ad identificare gli Ideal Day con i giorni di calendario, ignorando altre attività giornaliere dei membri del Team (ad esempio rispondere alle email) e ottenendo una stima spesso divergente dai tempi reali e meno incline ad essere corretta, non prevedendo un analogo della Velocity. Inoltre, la stima per Ideal Day non spinge a ragionare in funzione delle attività cross-functional, ma a silos. Infine, la stima è molto più “soggettiva” che “oggettiva” proprio perché tale è la definizione stessa di Ideal Day.
Una metafora utile per spiegare la differenza tra Story Point ed Ideal Day è quella della valutazione di un “sentiero”: due corridori possono concordare sul fatto che il sentiero è di circa 1 Km (lunghezza, Story Point) ma entrambi avranno una misura diversa per quel che riguarda la stima del tempo di percorrenza (timing, Ideal Day) che deriva dalla loro velocità. Mentre sulla prima questione è più semplice che raggiugano un accordo, sulla seconda è decisamente più difficile.
Detto questo, l’implicito suggerimento è quello di usare gli Story Point.
Una volta ottenuta l’approvazione del progetto, possiamo calarci nell’ Iteration Estimation, che si preoccupa di stimare la quantità di lavoro che il Team è in grado di fare per singola iterazione. Tale stima riguarda un lasso di tempo molto più ridotto (tipicamente 2-4 settimane) e quindi può essere sin da subito decisamente più accurata.
Le User Story vengono splittato in Task, ovvero si passa da una descrizione delle funzionalità desiderate dai key stakeholder ad attività di sviluppo vere e proprie, che vengono stimati in Ore.
E qui sorge spontanea una domanda: perché per le User Story si utilizzano gli Story Point e per i Task le Ore? Ebbene la risposta si trova proprio nel diverso scopo della tipologia di stima a cui afferiscono. Gli Story Point sono molto utili per dare una visione complessiva della complessità del progetto, laddove una stima in Ore avrebbe poco senso, visto che, all’inizio delle attività, sono troppi i fattori ancora incerti (si pensi, ad esempio, alla necessità di costituire un nuovo Team). Dualmente le “Ore” sono uno strumento molto più efficace per stimare singole attività che dovranno essere realizzate dal Team.
Si tenga presente che non esiste una relazione diretta tra Story Point e Ore (totali dei Task): se in generale è vero che ad una User Story di “peso” 2X, con molta probabilità, è associato un effort in Ore superiore ad una User Story di “peso” X, ciò non può essere considerata una verità assoluta.
Ad esempio, una User Story che prevede la visualizzazione dei dati in una griglia: As a User I want view my data in a grid format, se sviluppata da un Team fortemente skillato avrà una bassa complessità (Story Point), ma potrebbe richiedere molto tempo di implementazione cumulativo se tra i test di accettazione è previsto che bisogna verificarne il funzionamento con 10.000 tuple e quindi si rende necessario popolare di conseguenza il database.
A questo punto si evince che non è conveniente (anche se è possibile farlo) stimare il numero di User Story da sviluppare il una iterazione sfruttando la Velocity (velocity-driven) perché potrei incappare in situazioni come la precedente (basso Story Point ma molto tempo necessario per il data entry). Al contrario risulta più adeguata la prassi di selezionare una Story Point per volta (rispettando le relative priorità nella Work Item List), splittarla in Task, valutarne le ore e verificare se il Team si “impegna” a sviluppare altre User Story, ripetendo lo stesso ragionamento iterativo. L’approccio è quindi commitment-driven.
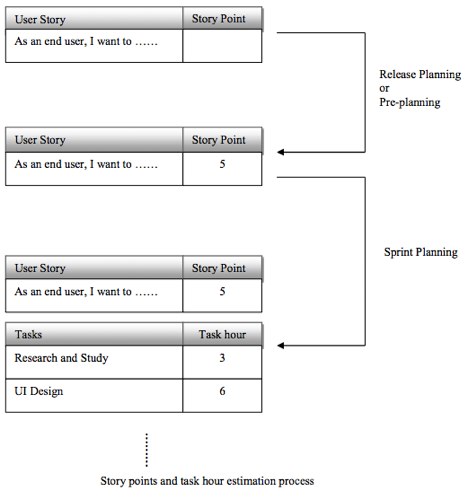
Combinando le due tecniche si riesce a pianificare le attività in modo più convincente, raffinando il tutto man mano che si completano le iterazione e fornendo semplici ma efficaci strumenti grafici di verifica come i Release e gli Iteration Burndown Chart.







